Analyzing by user group or other criteria
Splitting our analysis by user group or other criteria (such as region) is a common need, especially for larger websites.
Analyzing by user group
If we have more than one user group visiting our site (and most of us do), analyzing a tree test is a lot easier if we analyze each user group separately.
If we run a separate tree test for each user group (as we discussed in Different tasks for different user groups in Chapter 7), then we’re going to have a separate set of results for each test, so that’s already taken care of.
If, however, we run a single tree test across all of our user groups, we recommend doing a separate analysis for each group. That way, we can see the differences in their performance, instead of having their respective highs and lows mushed together into middling scores.
Suppose, for example, that we were looking at the results for a single tree test of the Shimano website. In Which part of the tree? in Chapter 6, we saw that Shimano has 3 major types of users – cyclists, anglers, and rowers. And suppose that the cyclists and anglers had no problem with tasks that covered the Corporate section of the site, but rowers failed miserably at those. If we looked at the results of all users together, the high scores of the cyclists and anglers would get mixed in with the low scores of the rowers, and we would just see a middling composite score, with no easy way to find out what caused it.
If, however, we could separate the groups and do the same analysis for each group, we could see that it was the rowers who had problems – the other two groups were just fine.
In Adding survey questions in Chapter 8, we suggested using survey questions to identify user groups, so we could easily pull them apart later for analysis. Now that we’re ready to analyze the data, we need to:
- Narrow the results to a single user group by filtering the data to only include participants who chose that user group in the “who are you” survey question.
- Regenerate the results (if this is not done automatically).
Here’s an example where we want to see if there are differences between members, prospective members, and the general public.
To get the results for prospective members, we filter our data set using a "who are you" survey question:
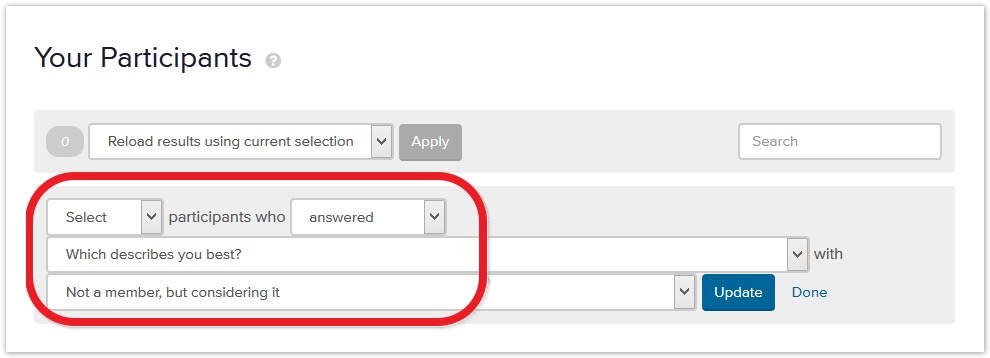
That selects 26 participants. We now we regenerate the results based on that subset of prospective members:
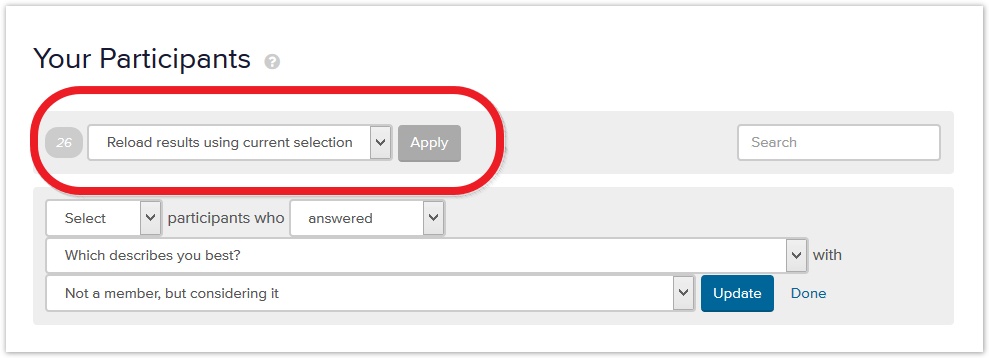
Once we’ve generated the results for each group, analysis proceeds as we’ve described elsewhere in this chapter. But at each step of the analysis (success rates, backtracking, first clicks, etc.), we can compare how the groups performed and look for any major discrepancies between them.
Analyzing by other criteria
Just as we can split our analysis by user group, we can do the same for other factors such as:
- Region
- New vs. existing customers
- Age or life stage
- …and so on.
In all cases, we need to either:
- Run separate tree tests for each cohort.
For example, if we’re analyzing by region, we could run separate tests for region 1, region 2, and region 3.
If we intend to use different tasks for the different groups, then we should definitely run separate tests – see Different tasks for different user groups in Chapter 7. - Run a single test, using a survey question to identify each factor.
If we’re intending to use the same set of tasks for each cohort, we could add a “Which region do you live in?” survey question, then filter the results using the various values of this question (as described above for user groups).
Next: Discovering evil attractors
Copyright © 2016 Dave O'Brien
This guide is covered by a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.