Different tasks for different user groups
So far, we’ve assumed that we’re creating a list of tasks for all of our participants to try – that is, a single pool of tasks that doesn’t care about who each participant is or what they know.
The reality is that our site is probably servicing several different user groups. As a power company, for example, we may have residential customers, farmers, and businesses. As a bank, we may have new customers we’re trying to convert, and existing customers we want to keep happy.
On the tree side, one of the biggest challenges for an information architect is to come up with a single site structure that works well for all major user groups. So we’re typically testing the same tree on all user groups. (We may be testing several variations of the tree, but each variation is being tested to make sure it performs well for all user groups.)
On the task side, however, we can’t always try the same set of tasks with every user group, because sometimes user groups are too different.
In Which part of the tree? in Chapter 6, we saw that the Shimano company has three major user groups – cyclists, anglers, and rowers - as reflected in their top-level navigation:

Suppose we create a list of tasks that includes cycling gear (e.g. bike chains), fishing information (e.g. tips on fly-fishing), and rowing specs (e.g. the weight of carbon-fibre oars). Then we launch the tree test and invite people from all of these user groups to participate.
Imagine a cyclist participant, who knows nothing about fishing or rowing. They can reasonably attempt the cycling-related tasks, but they have no clue about the fishing and rowing tasks. It may be that they don’t understand the task and its terminology, or they understand it but don’t know the subject matter well enough to know where to look, or it may be that they just don’t care about it. In any case, their results will be suspect. If they skip the task or wander around a lot, we’ll never know if it was because they understood the task (but the tree didn’t work for them), because they didn’t understand the task at all, or because they had no interest in that task. The result is the same - garbage in, garbage out.
We should only ask participants to do tasks that their user group might conceivably do on the real site. It doesn’t have to be something they have actually done themselves, but it should be something that they might reasonably expect to do at some point.
Reasonable pretending
There’s also a middle ground that comes up frequently – tasks that a given user group may not do, but that they could reasonably “pretend” to do, because the knowledge is not too specialized.
Suppose we are redesigning a bank site, and the two user groups we’ve identified are prospective customers and existing customers. We’ve jotted down tasks for each group, and we’re deciding if we can test them all together – a single tree test with a single, combined group of tasks.
Will either user group run into a task that they don’t understand, or that they couldn’t pretend to switch hats for and have a reasonable chance of success?
- The existing customers were once prospective customers, so they should be able to do a good job pretending. Yes, they know more about the bank than new customers, but we may decide that this is OK to ignore for the purposes of this study.
- The prospective customers may not know as much as existing customers about this particular bank site, but they are presumably existing customers at another bank, so they may know enough to be able to pretend to be existing customers.
So, in this example, it’s probably OK for us to give the same set of tasks to both user groups. We’ll still need to identify which participant belongs to which user group, but this is easily done using survey questions – see Adding survey questions in Chapter 8.
Not all pretending is reasonable, though. If we’re designing a medical site that serves both patients and doctors, it’s unlikely that either group could reasonably pretend to be the other:
- Medical knowledge is highly specialized – doctors have it (lots of it) and most patients don’t.
- Even for the same medical topics, doctors and patients use different terminology.
- They are probably going to be looking for different things, in different ways, on the site.
In this case, we would almost certainly give each group their own set of tasks, which means running a separate test for each group.
Mixing and splitting user groups
There are also cases where some user groups are similar enough that they can share tasks, and other user groups are different enough that they need their own set of tasks.
Recall the power company we mentioned earlier. They had the following groups of customers:
- Residential customers
- Farmers
- Small/medium business
- Large business
For this tree test, we came up with a list of tasks that covered each of these groups. We then reviewed each task to see if there were any user groups that wouldn’t normally do that, or couldn’t reasonably pretend to do it.
- Every customer has a home, so all the residential tasks were good to go.
- The farm tasks and small-business tasks were a bit more specialized, but nothing that a home customer would have trouble understanding. We did tweak the wording a bit to be less technical on certain tasks.
- The corporate tasks were mixed – some were general enough that anyone could understand and pretend to do them, but some were quite specialized (e.g. signing up as a customer using a tender process) and we didn’t think the other user groups would reasonably be able to do those.
This suggested that we should:
- run one tree test combining residential, farm, and small-business participants
- run the corporate participants separately with their own set of tasks.
Tracking who can do each task
The simplest way to track who can do each task is adding an “Audiences” column to our spreadsheet, noting which user groups could reasonably do that task:
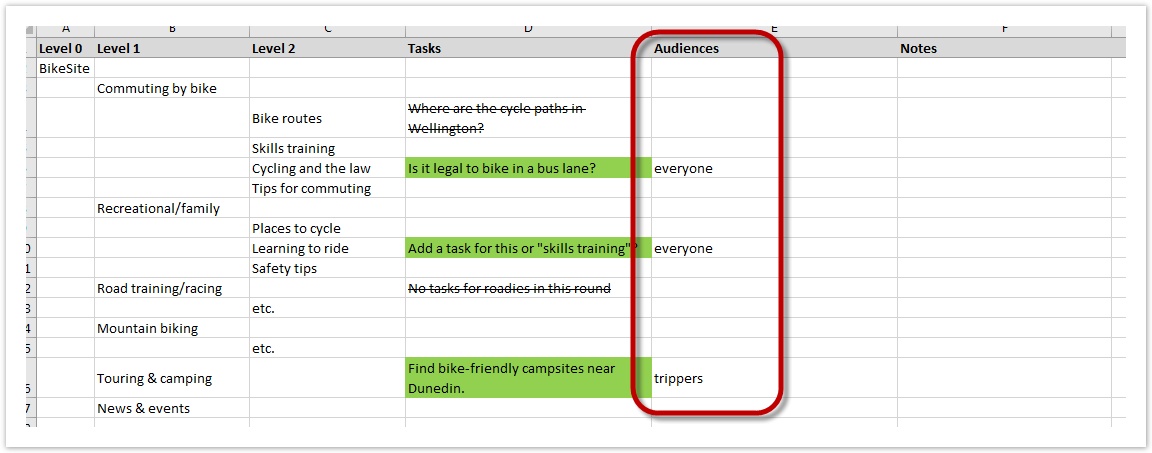
That usually suffices if there are only a few tasks that are specific to each group. But if it starts getting more complex, or we have several user groups, we may want to create a separate spreadsheet tracking tasks against audiences, like this:
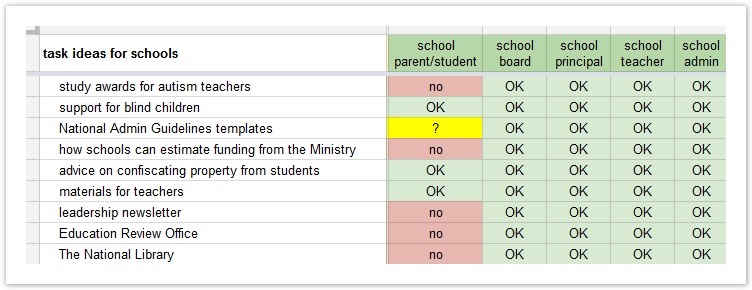
Splitting tests based on different tasks
In practical terms, different tasks for different users = different tests.
The simple case is that we find that all of our tasks could be reasonably attempted by all of our user groups. In that case, we could run a single tree test and invite everyone to participate. (We would still want to identify which user group each participant belonged to, so we can analyze for differences, but that’s a separate (and easy) nut to crack – see Adding survey questions in Chapter 8).
However, if we have tasks that some of our users cannot reasonably do (because those tasks are aimed at a different user group), we’ll need to set up separate tree tests.
Don’t panic – setting up a separate test for a specific user group is usually easy. We already have the tree (everyone is being tested on the same site structure), so we’re just changing out some tasks. Online tools typically have a “Duplicate Project” feature that makes it easy to copy and tweak the initial test setup.
When we set multiple tests based on different user groups, each test will usually have both of the following:
- Tasks that are common to all groups (e.g. “Find the company’s mailing address.”)
- Tasks that are specific to the target group (e.g. “You buy electricity for a large corporation. Does Acme Power use a tender process?”)
In the power-company example mentioned earlier, we determined that residential customers, farmers, and small business could all understand each other’s tasks, while corporate customers had some tasks that only they understood. We would then set the tests like this:
- Test 1 (residential, farms, small business)
- 14 non-corporate tasks
- 8 tasks shown to each participant
- Test 2 (corporate customers)
- 10 non-corporate tasks (a subset of the 14 above)
- 4 corporate tasks
- 8 tasks shown to each participant
This means that, once the tests are run, we can compare 10 of the 14 tasks across all user groups, while also getting data on 4 corporate-specific tasks. Most importantly, we did this without giving participants a task they couldn’t reasonably do.
Setting different tasks for different tests means that we’ll also need to check our coverage separately for each test. In the example above, we may decide that corporate customers are more likely to use the About Us section, so you may shift some tasks from other areas (e.g. power for farmers) to tasks targeted at About Us.
Next: Collaborating on tasks
Copyright © 2016 Dave O'Brien
This guide is covered by a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.